構造化データ(構造化マークアップ)とは
まずは本題( Google しごと検索の構造化データ)に入る前に、「構造化データ」について理解を深めましょう。
一般的に構造化データとは、【データストレージに配置される前に事前定義され、ある定められた構造となるように整形されたデータ】を意味します。
これだけだとまだピンと来ないですよね。もう少し分かりやすく表現すると、「ページに関する情報を機械が理解しやすいように、コンテンツの分類を促進させるための標準化されたデータ形式」です。
そして、同一の意味でよく使われる「構造化マークアップ」とは、構造化データを記述する作業(ウェブサイトに構造化データのタグをマークアップしていくこと)を意味します。
この記事で説明する、Google しごと検索枠に表示させることができる「求人情報( job posting )」の構造化データ以外にも、「FAQ(よくある質問)」や「ローカルビジネス」など、様々なデータタイプの構造化データが定められています。
FAQ 構造化データの設定方法 – よくある質問のリッチスニペット表示
https://strategy-code.com/marketing-colum/seo/structured-markup-of-faq/
求人情報の構造化データ
数あるデータタイプの構造化データの中の一つが「求人情報( job posting )」です。
求人情報の構造化データは、求人情報の公開日や有効期限、雇用形態、募集職種、求人情報の説明、雇用主の会社名、勤務地、給与などといった項目の情報を、定められた書式でソースコードに記述します。
構造化データには、「 Microdata 」「 JSON-LD 」などの種類の形式の記述方法がありますが、その中でも Google が推奨している形式は、「JSON-LD」です。実際の記述方法は、【求人情報 構造化データの記述方法】の章で詳しくご紹介します。
まずは、求人情報の構造化データを実装することで表示される、「 Googleしごと検索(英語名称:Google for Jobs)」について次章で詳しくみていきましょう。
求人情報 構造化データを実装するメリット
求人情報( job posting )の構造化データを追加することによって受けられる最大のメリットは、Google 検索結果の「しごと検索(英語名称:Google for Jobs)」の表示枠に掲載されることです。
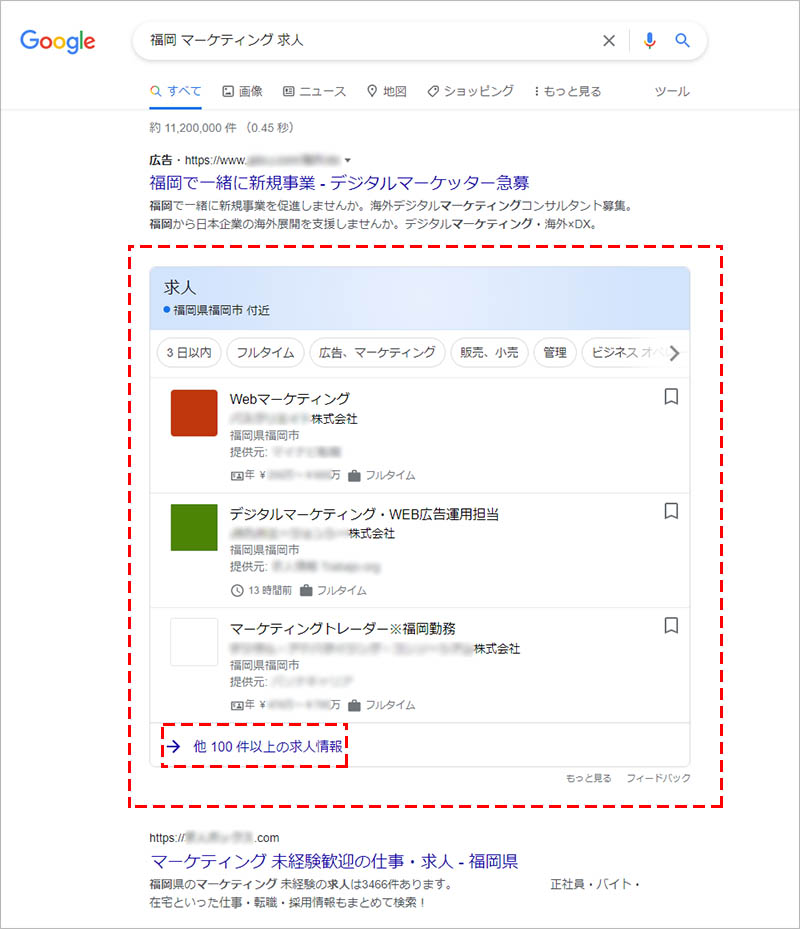
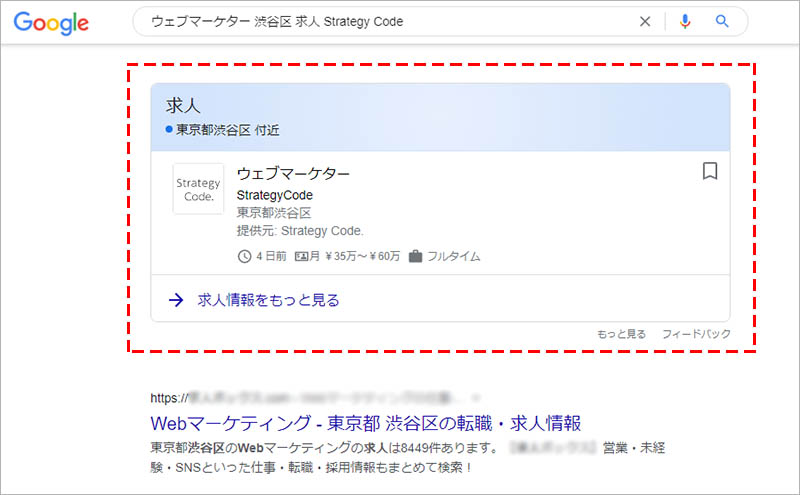
Google しごと検索(Google for Jobs)とは、Google 検索でユーザーが求人情報を求めていると機械が判断した検索クエリに対して、検索結果に表示する下の画像のようなリッチリザルトです。
この Google しごと検索(Google for Jobs)の表示枠に掲載されることで、求人情報の露出が増え、ウェブサイト(求人ページ)へのトラフィックの向上し、求人に対する応募者向上の可能性も期待することが出来ます。
Google しごと検索(Google for Jobs)とは
Google しごと検索( Google for Jobs )は多くの場合、検索結果のリスティング広告の表示枠の下部、オーガニック表示枠の上部の位置に、最大3件分の求人情報が表示されます。
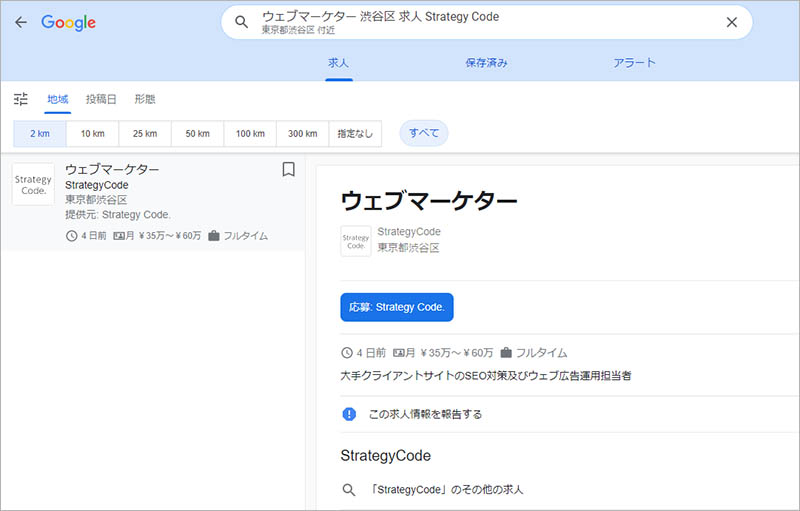
「他 〇〇件の求人情報」をクリックすると画面遷移し、該当する求人情報の一覧と、その求人の詳細が表示されます。
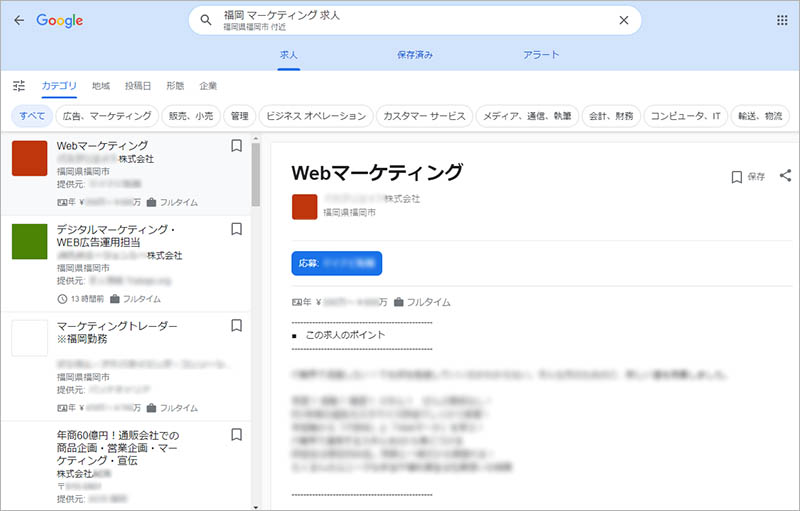
Google しごと検索( Google for Jobs )の表示枠に掲載されるためには、ウェブサイトに求人情報のページを用意し、そのページに構造化データを設置する必要があります。
求人情報 構造化データの記述方法
この記事では、Google が推奨している「 JSON-LD 」というコードを使った形式での求人情報の構造化データの記述方法を説明します。
JSON-LD の構造化データの形式は、ウェブサイトの対象求人ページの<head>タグ内、または、<body> タグ内に記載します。
標準(在宅勤務ではない)の求人情報の場合
記載するコードの形式(標準の求人情報の場合)は、以下のような例となります。
<script type="application/ld+json">
{
"@context" : "https://schema.org/",
"@type" : "JobPosting",
"title" : "募集職種(例:ウェブマーケター)",
"description" : "<p>求人情報の説明(例:大手クライアントサイトのSEO対策及びウェブ広告運用担当者)</p>",
"identifier": {
"@type": "PropertyValue",
"name": "求人情報を管理する組織・会社名(例:StrategyCode)",
"value": "求人情報の管理番号(例:01234)"
},
"datePosted" : "求人情報の公開日(例:2022-05-06)",
"validThrough" : "求人情報の有効期限(例:2022-05-30T00:00"),
"employmentType" : "雇用形態(例:FULL_TIME"),
"hiringOrganization" : {
"@type" : "Organization",
"name" : "雇用主の会社名(例:StrategyCode)",
"sameAs" : "雇用主の会社の公式サイトURL(例:https://strategy-code.com/)",
"logo" : "雇用主の会社のロゴ画像URL(例:https://strategy-code.com/wp-content/uploads/2021/07/cropped-icon.jpg)"
},
"jobLocation": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"streetAddress": "勤務地の町名番地(例:上原3-13-17)",
"addressLocality": "勤務地の市区町村(例:渋谷区)",
"addressRegion": "勤務地の都道府県(例:東京都)",
"postalCode": "勤務地の郵便番号(例:1510064)",
"addressCountry": "勤務地の国(例:JPN)"
}
},
"baseSalary": {
"@type": "MonetaryAmount",
"currency": "給与の通貨(例:JPY)",
"value": {
"@type": "QuantitativeValue",
"value": "基本給(例:350000 ※カンマ挿入不可 )",
"minValue" : "最低賃金(例:350000 ※カンマ挿入不可 )",
"maxValue" : "最高賃金(例:600000 ※カンマ挿入不可 )",
"unitText": "賃金形態(例:MONTH)"
}
}
}
</script>
標準(在宅勤務ではない)の求人情報の構造化データで、必須項目は上記の中の、
- title(募集職種)
- description(求人情報の説明)
- datePosted(求人情報の公開日)
- hiringOrganization の name(雇用主の会社名)
- jobLocation の @type(勤務地 “PostalAddress” を指定)
- jobLocation の streetAddress(勤務地の町名番地)
- jobLocation の addressLocality(勤務地の市区町村)
- jobLocation の addressRegion(勤務地の都道府県)
- jobLocation の postalCode(勤務地の郵便番号)
- jobLocation の addressCountry(勤務地の国)
このようになっています。
在宅勤務の求人情報の場合
在宅勤務の求人情報の場合は、以下のような例となります。
<script type="application/ld+json">
{
"@context" : "https://schema.org/",
"@type" : "JobPosting",
"title" : "募集職種(例:ウェブマーケター)",
"description" : "<p>求人情報の説明(例:大手クライアントサイトのSEO対策及びウェブ広告運用担当者)</p>",
"identifier": {
"@type": "PropertyValue",
"name": "求人情報を管理する組織・会社名(例:StrategyCode)",
"value": "求人情報の管理番号(例:01234)"
},
"datePosted" : "求人情報の公開日(例:2022-05-06)",
"validThrough" : "求人情報の有効期限(例:2022-05-30T00:00)",
"applicantLocationRequirements": {
"@type": "Country",
"name": "在宅勤務の国の要件(例:JPN)"
},
"jobLocationType": "TELECOMMUTE",
"employmentType": "FULL_TIME",
"hiringOrganization" : {
"@type" : "Organization",
"name" : "雇用主の会社名(例:StrategyCode)",
"sameAs" : "雇用主の会社の公式サイトURL(例:https://strategy-code.com/)",
"logo" : "雇用主の会社のロゴ画像URL(例:https://strategy-code.com/wp-content/uploads/2021/07/cropped-icon.jpg)"
},
"baseSalary": {
"@type": "MonetaryAmount",
"currency": "USD",
"value": {
"@type": "QuantitativeValue",
"value": "基本給(例:350000 ※カンマ挿入不可 )",
"minValue" : "最低賃金(例:350000 ※カンマ挿入不可 )",
"maxValue" : "最高賃金(例:600000 ※カンマ挿入不可 )",
"unitText": "賃金形態(例:MONTH)"
}
}
}
</script>
在宅勤務の求人情報の構造化データで、必須項目は上記の中の、
- title(募集職種)
- description(求人情報の説明)
- datePosted(求人情報の公開日)
- jobLocationType( “TELECOMMUTE” を指定)
- hiringOrganization の name(雇用主の会社名)
このようになっています。
指定できる employmentType(雇用形態)の種類
求人情報の構造化データの中に出てくる、「雇用形態( employmentType )」の指定は、以下のリストの中の項目の中から選択することができます。
| 雇用形態の種類 | 意味 |
| FULL_TIME | フルタイム(正社員) |
| PART_TIME | パートタイム |
| CONTRACTOR | 契約社員 |
| TEMPORARY | パートタイム(短期) |
| INTERN | インターン |
| VOLUNTEER | ボランティア |
| PER_DIEM | 日雇い |
| OTHER | その他 |
リッチリザルトテストツールで構造化データを確認する
構造化データの設置が完了したら、もしくは、設置する予定の構造化データの記述が固まったら、リッチリザルトテストツールで構文にエラーがないか確認しましょう。
公開 URL からテストする場合
リッチリザルトテストツールにアクセスして、「 URL 」のタブを選択した状態で、入力欄に構造化データを設置した対象ページの URL を入力し、「 URL をテスト」をクリックします。※ページを非公開にしているなど、ボットがクローリングできない状態ではテストは出来ないため、テストする場合はページを一時的に公開に切り替えましょう
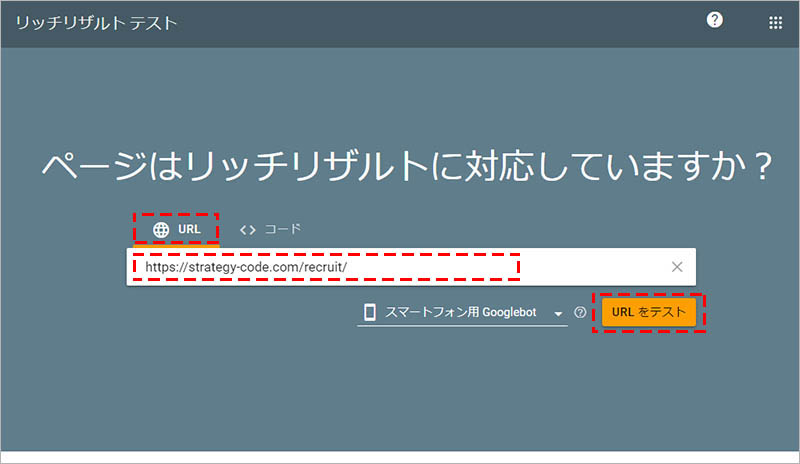
公開 URL のテストが完了すると、テスト結果の画面に切り替わり、「検出された構造化データ」の項目に「求人情報」が表示されます。「〇件の有効なアイテムを検出されました」と表記されていれば、問題なく構造化データが設置されています。
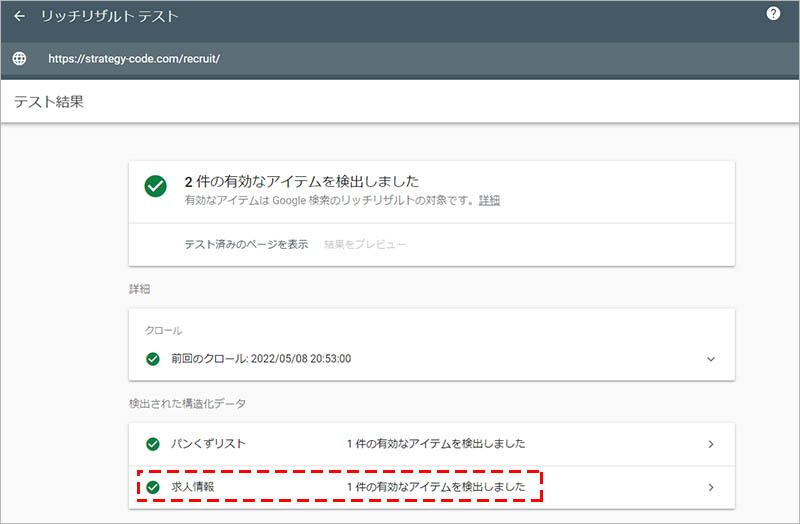
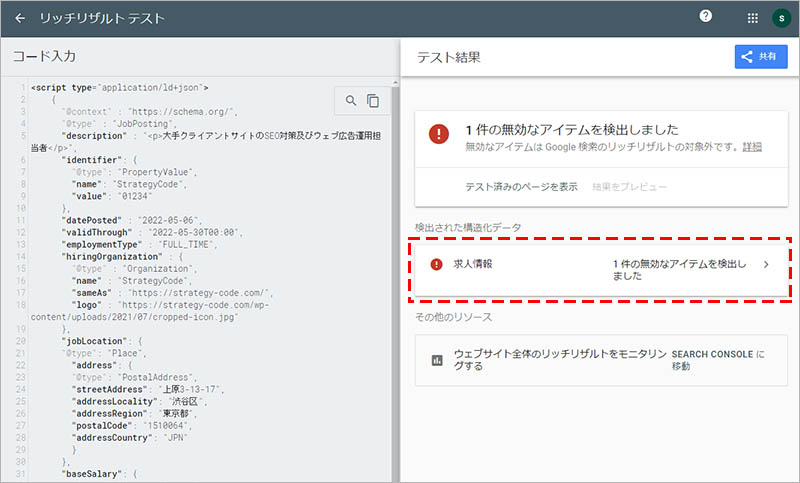
構文にエラーがある場合は、「〇件の無効なアイテムを検出しました」と表記されるので、エラー内容を確認するために、その項目をクリックします。
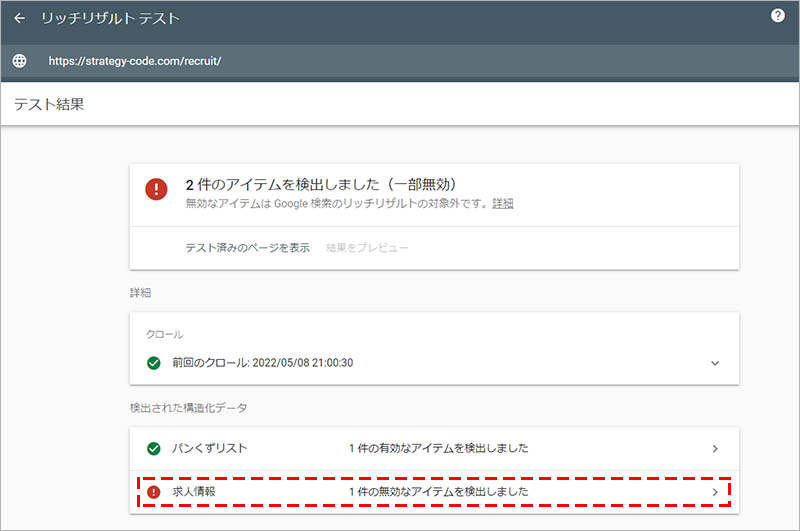
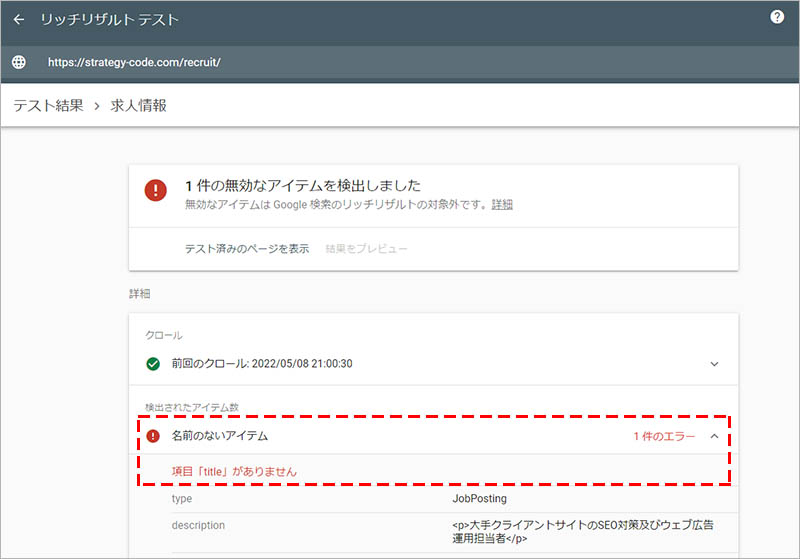
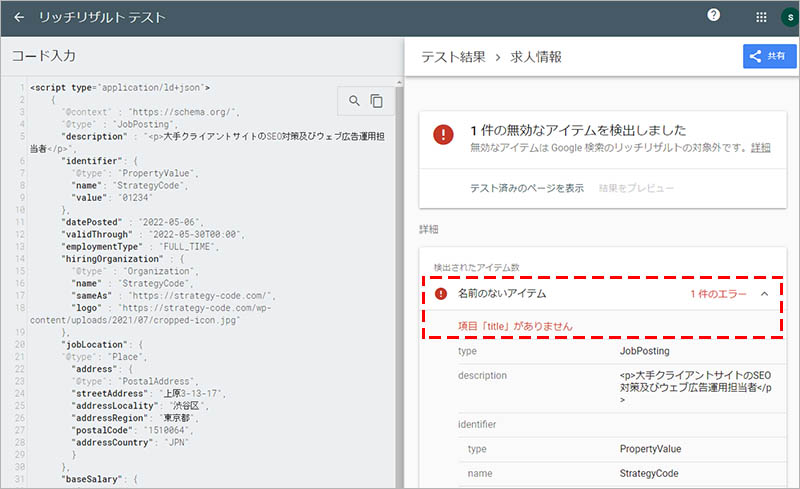
「詳細」の欄で、エラーの内容を確認し、該当箇所の構文を修正してください。※下画像は、必須項目である “title” の設定が漏れていた場合の例です。
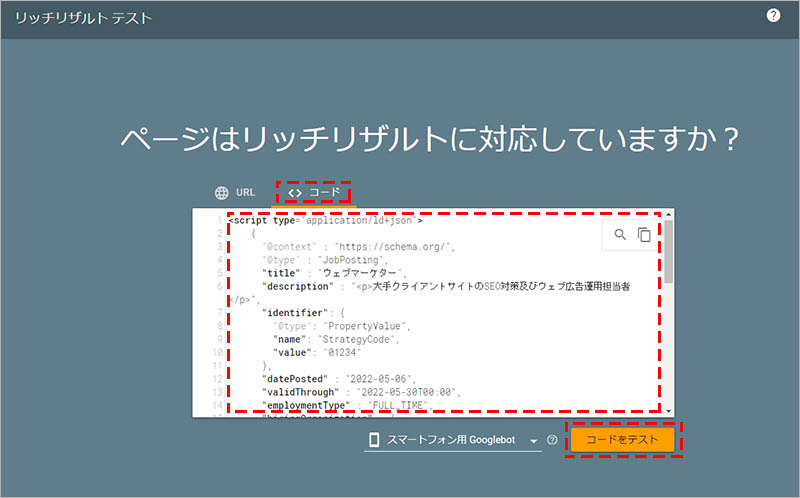
コードからテストする場合
リッチリザルトテストツールにアクセスして、「コード」のタブを選択した状態で、入力欄に設置した構造化データのソースコードをペーストし、「コードをテスト」をクリックします。
コードのテストが完了すると、テスト結果の画面に切り替わり、「検出された構造化データ」の項目に「求人情報」が表示されます。「〇件の有効なアイテムを検出されました」と表記されていれば、問題なく構造化データが設置されています。
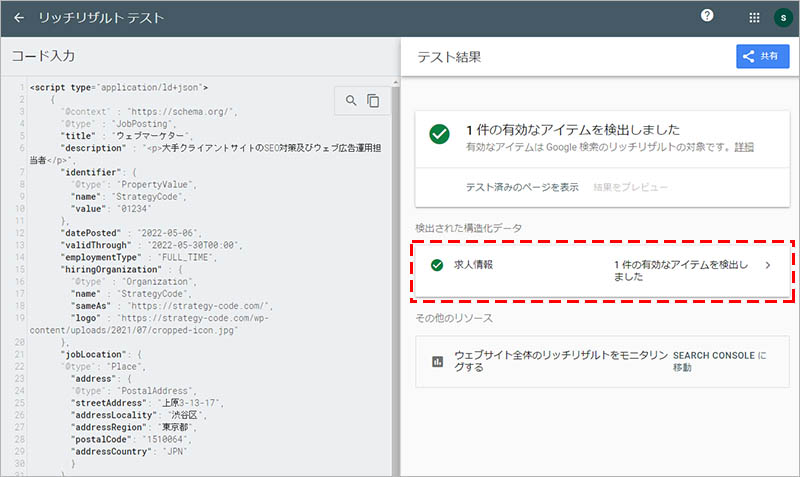
構文にエラーがある場合は、「〇件の無効なアイテムを検出しました」と表記されるので、エラー内容を確認するために、その項目をクリックします。
「詳細」の欄で、エラーの内容を確認し、該当箇所の構文を修正してください。※下画像は、必須項目である “title” の設定が漏れていた場合の例です。
構造化データ設置後は、Google にクローリングを申請する
設置した構造化データは、Google が対象ページを巡回(クロール)しにきたタイミングで読み込まれます。
クローラーは、「外部サイトからの被リンク」や「サイト内の内部リンク」、「サイトマップ」などを辿ってウェブページをクローリングします。
上記のいずれかを満たしていれば、大抵の場合は、サイト運用者側からクローリングを申請せずとも、いずれクローリングしてくれます。
そのため、クローリングの申請はマストではありませんが、いつクローリングしに来てくれるか分からないので、少しでも早めるためにも、以下のいずれかの対応を行うことをおすすめします。
インデックス登録をリクエストする方法
Google Search Console から、構造化データを設置したページの URL 検査を行い、「ページを変更しましたか?」という表示の横にある「インデックス登録をリクエスト」をクリックして、クローリングを申請します。
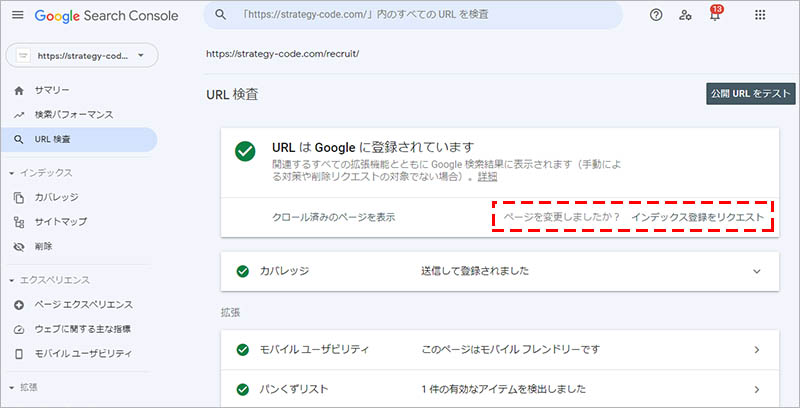
サイトマップを送信する方法
最終更新日の記載の入った XML サイトマップを用意します。
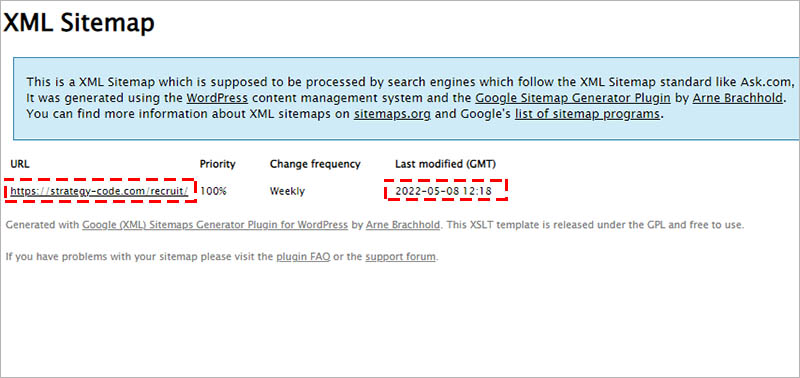
XML サイトマップを用意したら、Google Search Console から、サイトマップのURLを指定してサイトマップを送信します。
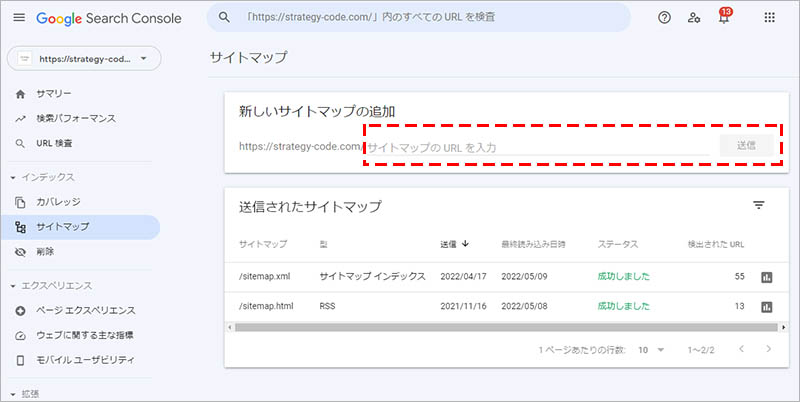
※既にサイトマップを送信している場合は、そのサイトマップのリストの中に対象ページの URL と最終更新日の情報がしっかりと入っているか、念のため確認しましょう
Indexing API を送信する方法
Indexing API とは、Google が提供している数ある API の中の一つです。Indexing API が最も早くクローラーに対して指示を出せるため、求人情報ページのクロール申請に関して Google は、Indexing API を使用することを推奨しています。
参考:Indexing API クイックスタート | Google Developers
この記事の執筆時点(2022年5月)では、Indexing API は、求人情報( JobPosting )や、ライブ配信動画( VideoObject の BroadcastEvent )の構造化データが設定されているページをクロールするためにのみ使用できます。
API 連携を実装するためには、API キーの発行、Search Console で所有権の確認、アクセストークンの取得など、いくつかの技術的な工程があるため、具体的な手順は以下の記事で説明します。
Indexing API の特徴や注意点、WordPress での設定方法を詳しく解説
https://strategy-code.com/marketing-colum/seo/indexing-api/
ただし、Indexing API を使用する場合でも、サイトマップの送信は行うようにしましょう。
Search Console の拡張項目を確認する
求人情報の構造化データを設置した対象ページを Google がクローリングして読み込まれると、Search Console の「拡張」の項目に、「求人情報」が表示されるようになります。
検出されたリッチリザルトと、Google でそのリッチリザルトが読み取られたかどうかを確認することが出来ます。
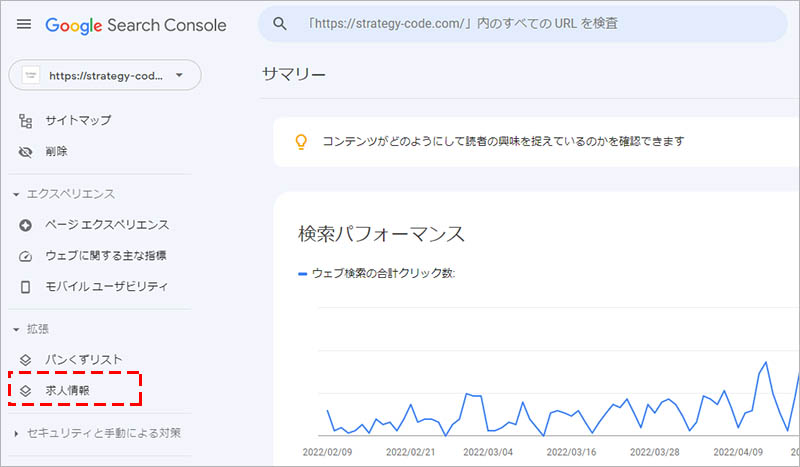
「求人情報」をクリックすると、「有効」「有効(警告あり)」「エラー」の ステータス を確認できるので、「詳細」に表示されているステータスをクリックします。
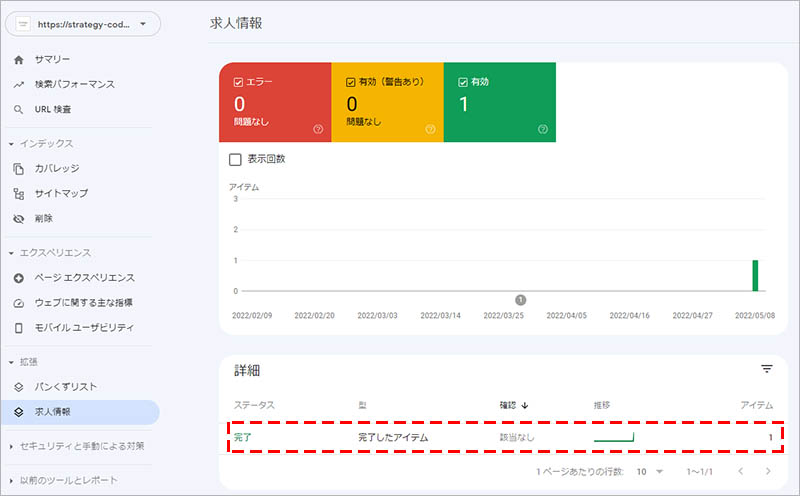
「 URL 」に該当ステータスのページ URL 、「項目名」に職種、「最終検出」に最後に読み込まれた日付が表示されます。
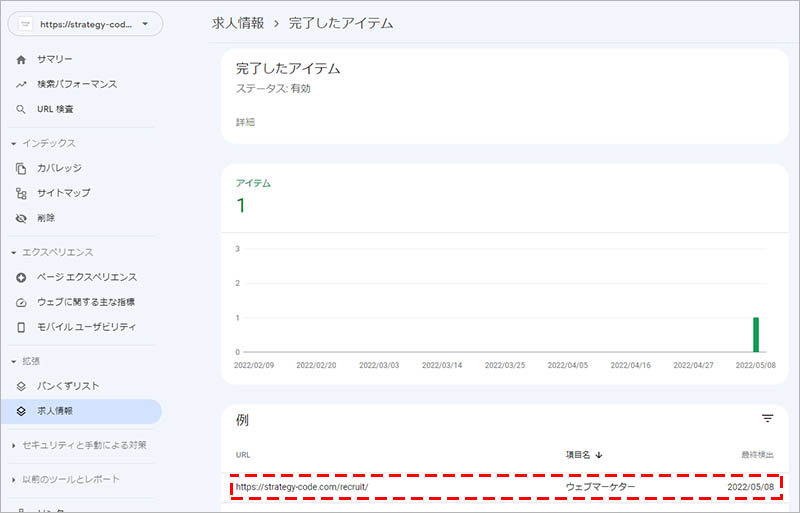
有効のステータスに該当ページのURL があることを確認出来たら、実際に Google で検索を行い、Google しごと検索( Google for Jobs )に掲載されているかどうかを確認しましょう。
※下画像の求人は、当記事執筆用にテストした架空の求人情報です
まとめ
いかがでしたでしょうか?今回は、Google しごと検索( Google for Jobs )に掲載することの出来る、求人情報の構造化データの設置方法について説明しました。
求人情報( job posting )は数ある構造化データのひとつですが、Google しごと検索(Google for Jobs)の表示枠に掲載されることで、求人情報の露出が増え、ウェブサイトへのトラフィックの向上を見込むことができます。
様々な業種で人材不足や、採用コスト増が叫ばれている昨今において、事業者にとっては、求人の応募者数獲得の可能性を上げるためにも、是非とも設定しておきたいですよね。