ロボットテキスト(robots.txt)の役割
「ロボットテキスト(robots.txt)」とは、クローラーなどのアクセスを制御するためのテキストファイルです。
サイト運用者は、このロボットテキストを活用して、検索エンジンのクローラーがアクセスできるページ、またはアクセスを制御するページを指定することができます。
Google側は、主にウェブサイトでのリクエストのオーバーロードを避ける目的でロボットテキストを使用するべきとしており、ページが検索で表示されないようにするためのメカニズムではないとしています。
もし、ページが検索で表示されないようにするという目的であれば、下記に挙げるような対応を推奨しています。
- noindex を使用してインデックス登録をブロックする
- ページにパスワード保護をかける
参考:robots.txt の概要とガイド | Google 検索セントラル | ドキュメント | Google Developers
次章以降で、クローリングの仕組みや noindex との違い、ロボットテキストの実際の設定方法について、詳しく見ていきましょう。
クローリングとは
「クローリング (Crawling)」とは、ロボットがウェブサイトのリンクをたどって、そのウェブページに含まれる情報を収集することです。
検索エンジンによって行われるクローリングは、自動的にプログラムされたロボット(Robot)によって行われ、収集した情報を元に、追加する価値があると判断したものを検索エンジンのインデックスに登録します。
現在の検索エンジンの仕組みでは、クローリングは正確で最新の情報を検索結果に表示するために絶対的に必要なプロセスと言えます。
クローリングは、ユーザーに高品質な検索結果を提供するために、とても重要な役割を果たしているのです。
noindex と robots.txt の違い
ここで、混同されがちな「noindex」と「robots.txt」の違いを説明します。
まず「noindex」は、検索エンジンのインデックスから除外することを目的に使用します。特定のページに「noindex」を指定することで、インデックス登録から除外され、特定のページのクローリング頻度は落ちますが、対象ページがクローリングされないというわけではありません。つまり「noindex」は、クローリング制御の目的で使用するものではないということです。
逆に「robots.txt」ですが、これはクローリングを制御することを目的に使用します。「robots.txt」は、特定のページにクローラーのアクセスを許可する or 許可しないかを指定できます。「robots.txt」で特定のページのアクセスを拒否した場合、基本的にはそのページはインデックスに登録されにくくなりますが、必ずしもその限りではありません。つまり「robots.txt」は、インデックスから除外することを目的に使用するものではないということです。
冒頭の【ロボットテキスト(robots.txt)の役割】の章でも述べましたが、「robots.txt」は、主にウェブサイトでのリクエストのオーバーロードを避けるという、クローリング制御の目的で使用するべきとされています。
robots.txt(ロボットテキスト)の構成要素
ロボットテキストは基本的に、「User-Agent」「Disallow」「Sitemap」という3つの要素で構成されます。
例えば、WordPress の場合の robots.txt のデフォルト設定は以下のようになります。
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://strategy-code.com/sitemap.xml
「User-Agent」「Disallow」「Sitemap」について、それぞれ詳しく見ていきましょう。
User-Agent
User-Agent には、クロール許可 or 不許可のルールを適用する対象(ユーザー エージェント トークン)を指定します。
先の WordPress のデフォルト設定の例では、
User-agent: *
上記のように、全てのクローラーを対象にする、* が記述されています。
全てのクローラーではなく、例えば Google の検索エンジンのクローラーのみを対象に指定したい場合は「*」ではなく、「Googlebot」と記述します。
検索エンジン以外の他の Google のユーザーエージェントトークンを確認したい場合は、下記を参考にしてください。
参照:Google クローラー概要(ユーザー エージェント一覧) | Google 検索セントラル
Disallow
Disallow には、クロール不許可のルールを適用するページを指定します。
先の WordPress のデフォルト設定の例では、
Disallow: /wp-admin/
上記のように、WordPress のログイン画面である、/wp-admin/ が記述されています。
特定のページではなく、例えばウェブサイト全体を対象に指定したい場合は、「/」と記述します。
特定のディレクトリ配下のページ全体を対象に指定したい場合は、「/blog/」のように、対象ディレクトリを記述します。
Allow
Allow には、Disallow で指定したクロール不許可のディレクトリの内、クロール許可のルールを適用するページを指定します。
先の WordPress のデフォルト設定の例では、
Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
上記のように、クロール不許可としている WordPress のログイン画面である、/wp-admin/ の配下の、 /wp-admin/admin-ajax.php へのクロールは許可するよう記述されています。
Sitemap
Sitemap には、対象サイトのサイトマップファイルの URL を記述します。
Sitemap は必須項目ではありませんが、検索エンジンにサイト内の構造や内容を的確で早い理解を促進するものです。
SEO(自然検索)対策を意識する場合は、用意した方が良いでしょう。
robots.txt の挙動を確認する方法
robots.txt のテキストファイルを作成・変更する場合は、意図した挙動になるように、Google Search Console の「robots.txt テスター」ツールを使用して挙動を確認します。
Google Search Console にログインしたら、「▼ 以前のツールとレポート」の項目の中にある、「詳細」をクリックします。
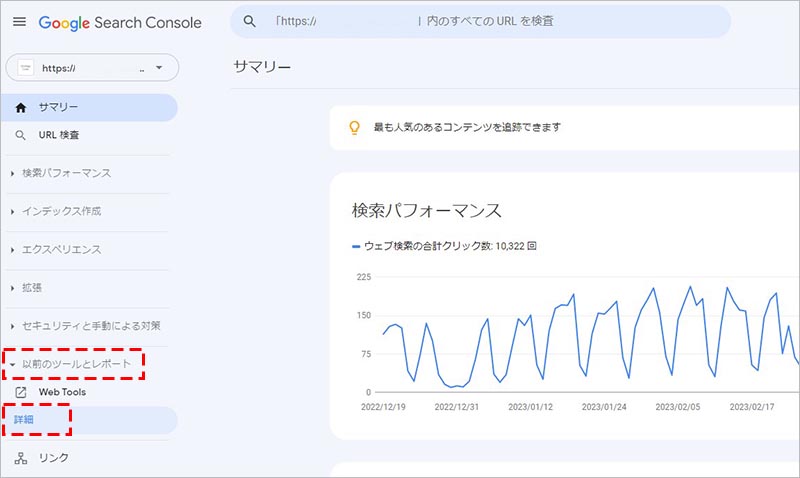
画面右側にメニューが表示されるので、その中にある、「robots.txt テスター」をクリックします。
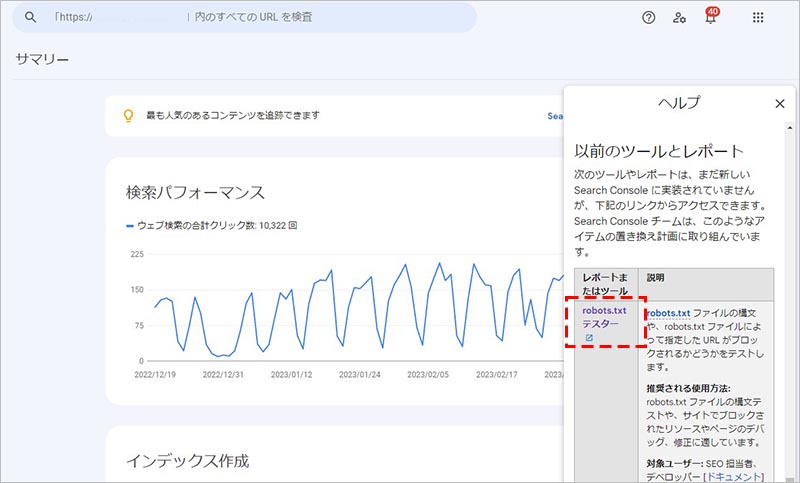
プロパティを選択する画面が表示されるので、対象サイトのプロパティを選択します。
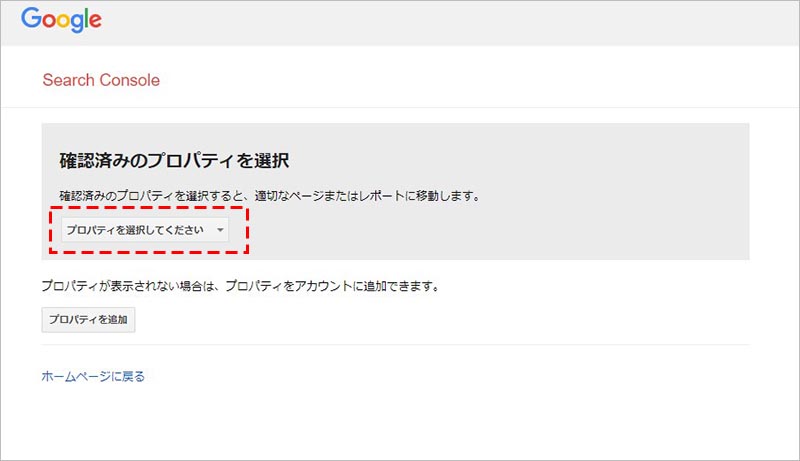
現在設定されている robots.txt の記述内容が表示されます。
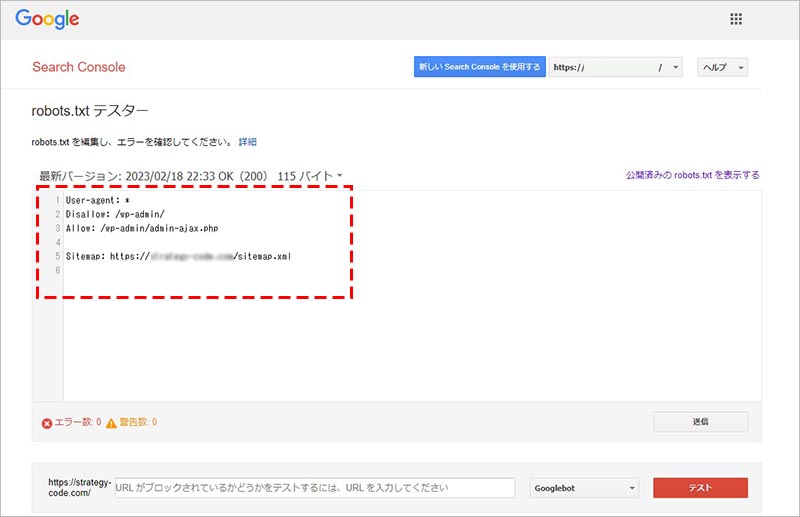
挙動をテストしたい記述に変更します。続けて、クロールを許可またはブロックされているかどうか確認したいURL(ページ path)を下の入力欄に記述して、「テスト」をクリックします。
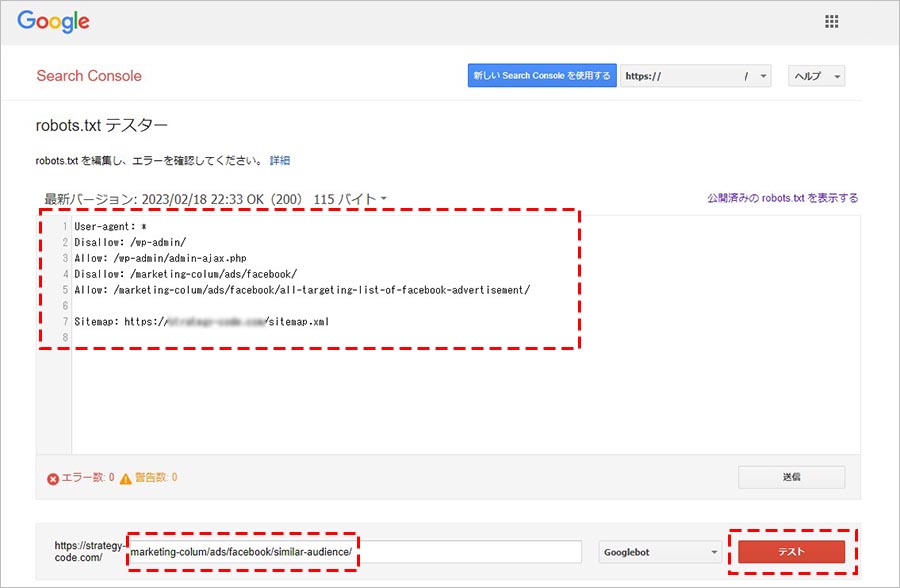
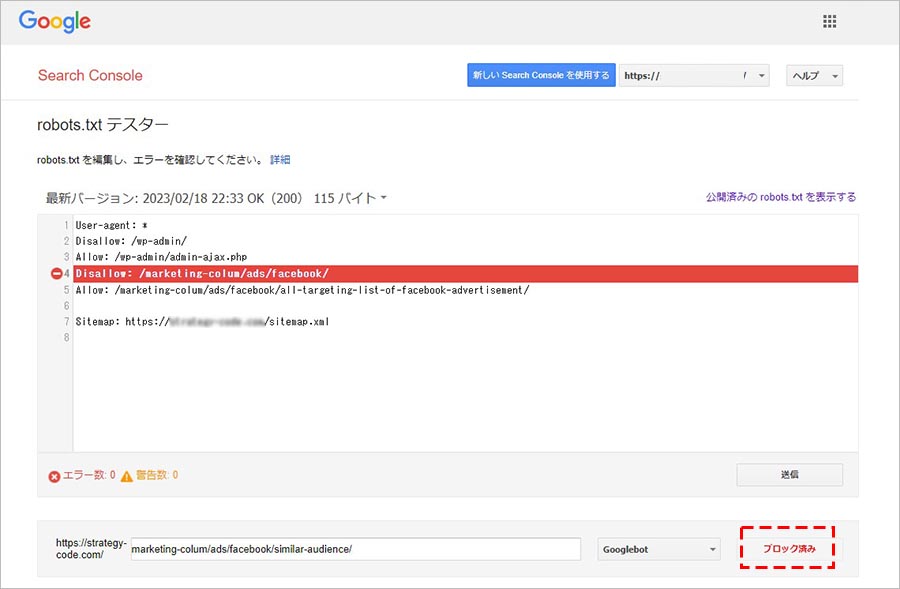
テスト結果が表示されます。テストした URL へのクローリングがブロックされている場合は、下の画像のように「ブロック済み」と表示され、robots.txt 内のどの構文でブロックしているかが赤くマークされます。
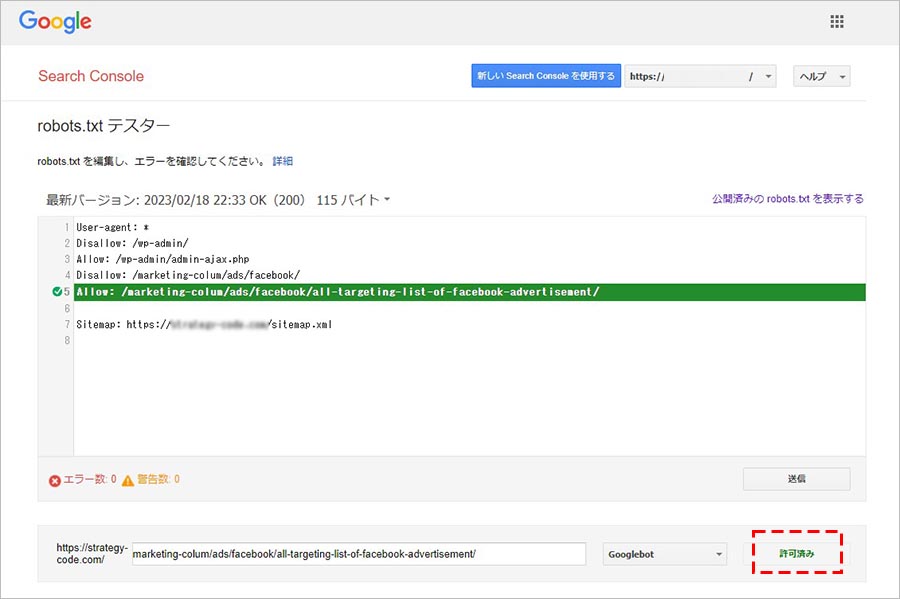
逆に、テストした URL へのクローリングが許可されている場合は、下の画像のように「許可済み」と表示されます。
この「robots.txt テスター」ツールは、あくまで挙動をテストするツールです。このツール上でrobots.txt ファイルに変更を加えても、実際にサーバーにアップロードしている robots.txt が上書きされるわけではありません。
挙動をテストしたら、次章にて、実際にサーバーにアップロードして設定します。
robots.txt ファイルの設置方法
前章で挙動を確認したら、その記述をコピーしてメモ帳などにペーストして、テキストファイル(.txt)の拡張子で保存します。
その際に、ファイル名を「robots」とするだけで、robots.txt のファイルデータ自体の準備は完了です。
あとは最後に、先ほど準備した robots.txt のファイルデータを、対象サイトの公開ディレクトリに FTP などでアップロードするだけで、設置完了となります。
設定時の注意点
インデックスに既に登録されているページに対して、robots.txt でクローリングを制御した場合でも、基本的にはインデックスには残り続けてしまいます。
もし対象ページをインデックス登録から除外したいという場合は、先に対象ページに noindex を設定して、インデックス登録から外れたら robots.txt でクロールを制御するという流れをとりましょう。
まとめ
いかがでしたでしょうか? 今回は、ロボットテキスト(robots.txt)の役割や構成要素、noindex との違い、設定時の注意点などについて解説いたしました。
通常規模のウェブサイトであれば、ロボットテキストを使用するケースはあまりないかもしれませんが、サイトの規模が大きくなるほど、クローリングを制御する必要性が生じることもあります。
必要に応じて、正しくクローリング制御の設定が行えるように、当記事の内容を参考に、基礎知識をしっかりと理解しておきましょう。